How we deploy at MixRadio
31 Oct 2014This post was lifted from the (now defunct) MixRadio dev blog which ceased to exist in April 2016. It has been amended slightly to remove out of date links.
In this post I’d like to talk about how we deploy our microservices into EC2 here at MixRadio. I’ll spend a bit a time explaining our old process and some of the problems it had and then I’ll go into more detail on the new Clojure tools we created to solve them.
Out with the old…
Deon has described our journey from monolithic, big-bang releases to continuous delivery. This was a change that was undertaken while we were running MixRadio out of our own datacenter.
As we became more comfortable with this new way of working we identified a number of flaws in the way we were deploying and running our services in the datacenter:
- Snowflake servers - Our servers were more than just an IP address and purpose. Configuration drift would see the servers gradually begin to differ as they lived longer.
- Provisioning the servers took too long - There were too many manual tasks involved in getting a new server up and running. We had Puppet to cover the basic bootstrapping but still had to enter the server’s details into our deployment tool and load balancers.
- Deployment time - As the number of instances increased, the time it took to deploy increased linearly. Not a desirable property if you want to maintain the ability to make frequent changes to a high-scale service.
- Configuration was murky - Changes made to configuration were tracked but it was unclear exactly what had changed and in the event of a rollback being required we would frequently find properties were not reverted.
Old deployment process
Our existing deployment process was the result of our transition to continuous delivery. The application which carried out deployments was created in-house and was beginning to show its age. We created it at a time when we were deploying a small number of applications to a couple of servers each for high-availability.
To make a change to our live platform you would log into a website, enter the version of the service you were deploying, perhaps amend the configuration and kick off your deployment. The deployment tooling would go through each server hosting the service, in turn. It would use SSH to remove the old version of the application and then the new version, with new configuration, would be installed. This process is shown below for an example four server deployment:
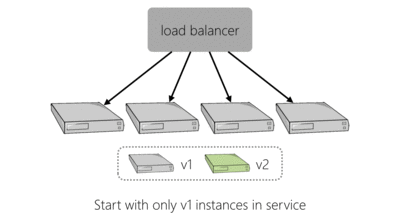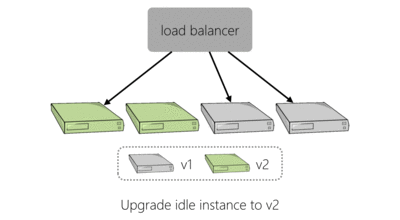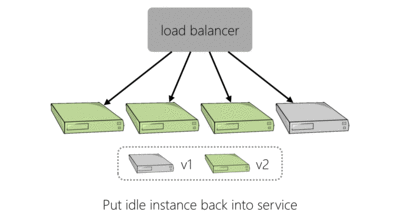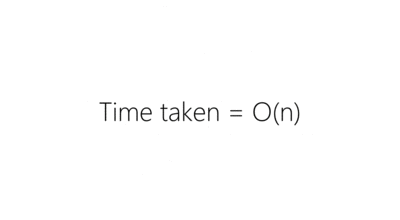
As we needed to deploy to more servers to handle additional load we found that this approach to deployment was slowing us down. In the event of failure, this method of deploying would also require linear time to perform the same operations in reverse which is bad if a deployment has caused things to go haywire.
We’d been steadily increasing the number of microservices we were running and the existing process wouldn’t allow the deployment of more than one service to an environment at a time. This was a self-imposed restriction we’d chosen back when we were starting out with continuous delivery because we weren’t happy with more than one piece of the platform changing at a time. We felt that it would make it difficult to determine where any regression or failure had come from if more than one thing was in-flight at a given time. Since that decision was made we’d become more adept at monitoring our services and the platform as a whole so we were keen to see how we would get on without enforcing that restriction in the new world.
… in with the new
Last year, we knew that we wanted to migrate out of the datacenter and into AWS. It was a good time for us to change our deployment process and we had a vague idea of what it might look like from reading about other teams’ tools.
We knew some of the drawbacks of our current process but wanted to make sure we avoided making the new tools painful as well. We used a large whiteboard in the office to let people put up suggestions for functionality the tools should have or things we should consider in the overall design.
After about a month a group of developers got together and went through the suggestions. They were prioritised and became the goals for the team developing our new tooling. We wanted to begin migrating services to EC2 as soon as possible but had to balance that with making sure everything was working smoothly. We decided that the easiest way to get the tooling up and running was to attempt to do everything required to deploy:
- A skeleton service which represented a typical service with no dependencies.
- An actual service which had dependencies on other services already running in our existing datacenter (this was important because we knew that we weren’t going to be doing a big-bang migration).
- The services which formed the tooling itself.
It was felt these would allow us to dogfood to a point where we were comfortable everything was working safely and the process reflected what we’d like to be using as developers. From there we would be able to open up the tooling to other developers who could begin the migration.
We had six services which we’d need to create to form the tooling and provide the experience we were looking for:
Metadata
We had multiple copies of what was essentially the same list of services: we had one in our logging interface, one in the deployment application and others which all had to be kept up-to-date. We wanted to create a service which just provided that list and meant that anyone who wanted to iterate over the services (including our own tooling) could do so from one canonical source. We also realised that we could attach arbitrary metadata to those service descriptions which would allow us to answer frequent questions like ‘who should I go to with questions about service X?’ and ‘where can I find the CI build for service Y?’.
We created a RESTful Clojure service which exposes JSON metadata for our services. The metadata for each application can be retrieved individually and edited one property at a time. The minimal output for an application ends up looking something like this:
{
"name": "search",
"metadata": {
"contact": "someone@somewhere.com",
"description": "Searching all the things"
}
}
The important thing here is that there’s no schema to the metadata. We have a few properties which are widely used throughout the core tooling but anyone is free to add anything else and do something useful with it.
Baking
Having seen the awesome work the guys at Netflix have done with their tooling we knew that we liked the idea of creating a machine image for each version of a service rather than setting up an instance and then repeatedly upgrading it over time. We already knew we had a problem with configuration drift and using an image-based approach would alleviate a lot of our problems with snowflake servers. Even if someone had made changes to an individual instance they would be lost whenever a new deployment happened or the instance was replaced. This pushes people towards making every change repeatable.
We were aware of Neflix’s Aminator which had just been released. However we had a few restrictions around authentication that made it difficult to use and wanted a little more flexibility than Aminator provided.
Our baking service is written in Clojure and shells out to Packer which handles the interactions with AWS and running commands on the box. We split our baking into two parts to ensure that baking a service is as fast as possible. The first part takes a plain image and installs anything common across all of our images. This is run once a week automatically, or on demand when necessary. The second part, which is much quicker, installs the service ready to be deployed.
Configuration
To handle differing configuration across our environments we created a service to store this information. We wanted to provide auditing capabilities to see how configuration had changed and have confidence that when we rolled back, we were reverting to the correct settings.
We were busily planning away and thinking about how to solve the problem of concurrent updates to configuration and how to store the content when we realised that we actually already had the basics for this service on every developer’s machine. We’d veered dangerously close to attempting to write our own Git. It (thankfully) struck us that we could build a RESTful service (in Clojure, of course) which exposed the information within a Git repository. Developers wouldn’t make changes to the configuration via this service, it would be read-only. They would use the tools they’re familiar with from the comfort of their own machine to commit changes. Conflicts and merges would then be handled by software written by people far cleverer than us and auditing is as simple as showing the Git log.
For each service and environment combination we have a Git repository containing three files which allow developers to control what’s going to happen when they deploy:
application-properties.json- The JSON object in this file gets converted to a Java properties file and the service will use this for its configuration.deployment-params.json- This file controls how many instances we want to launch, what type of instance they’ll be etc.launch-data.json- This file contains an array of shell command strings which will be executed after the instance has been launched. This functionality doesn’t tend to get used for most services, but has allowed us to automatically create RAID disks from ephemeral storage or enable log-shipping only in certain environments.
We originally thought that we could just grab the configuration, based on its commit hash, from the configuration service during instance start-up. However, we realised that our configuration service could be down at that point, or the network could be flakey. That’s not a huge problem if someone is actively deploying but if the same situation occurs in the middle of the night when a box dies, we need to know there is very little that can stop that instance from launching successfully. For this reason the configuration file and any scripts which run at launch (which are likely to differ from environment to environment) are created at launch time from user-data by cloud-init. User-data is part of the launch configuration associated with the auto scaling group and is obtained from the web-server which runs on every EC2 instance, making it a reliable place to keep that data. This method means that our service image can be baked without needing to know which environment it will eventually be deployed to, preventing us from having to bake a separate image for each environment.
Infrastructure management
The AWS console is an awesome tool (and keeps getting better) but it’s not the way we really wanted to have people configuring their infrastructure. By infrastructure we mean things which are going to last longer than the instances which a service uses (for example: load balancers, IAM roles and their policies etc.). We’ve already blogged about this service, but the basic idea is that we like our infrastructure configuration to be version-controlled and the changes made by machines.
Deployment orchestrator
When we started developing our tooling we were pretty green in terms of AWS knowledge and were, in some ways, struggling to know where to start. We knew about Netflix’s Asgard and the deployment model it encouraged made perfect sense as the base for our move into AWS.
We started using Asgard but found that our needs were sufficiently different that we ended up moving away from it and creating something similar. I’ll run through our initial use of Asgard before describing what we came up with.
Red-black deployment
While we’re on the subject of Asgard’s deployment model I’ll describe red-black (or green-blue, red-white, a-b) deployment in case anyone isn’t familiar with it. As shown in our existing deployment model above, we had a problem with the linear increase in deployment (and, perhaps more importantly, rollback) time. We also didn’t like the idea that, during a deployment, we’d be decreasing capacity while we switched out and upgraded each of the instances. A number of our services run on two instances not due to load requirements but merely to provide high-availability so a deployment of these services would result in the traffic split going from 50% on each instance to 100% on one instance. At this point, if anything happens to that single instance the service would be unavailable.
The red-black deployment model does a good job of solving these issues while also simplifying the logic required to make the deployment. Here’s our previous four server deployment in red-black style:
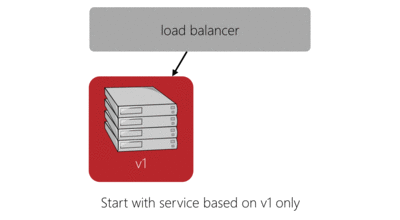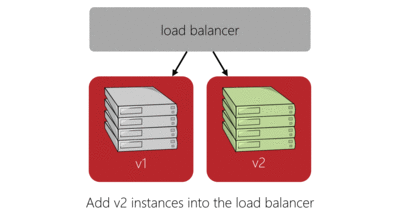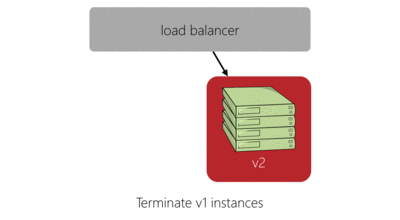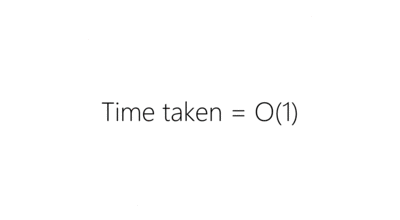
The main benefits of this deployment model are:
- Capacity is temporarily increased during deployment, rather than reduced.
- There are opportunities to pause the deployment process and evaluate the new version of the service under live load for any ‘unforeseen consequences’.
- Rollback is as simple as allowing traffic back onto the old version of the service and preventing traffic to the new version. How long we keep those instances alive after deployment is up to us.
- The unit of deployment we’re dealing with is an auto scaling group which encourages their use for any deployment whether to single or multiple instances. This pushes us to automate enough that if an instance is being troublesome (or if it simply dies during the night) we have the confidence that it will be terminated and another will take its place.
Back to the orchestration service…
This service is the way developers kick-off their deployments. It would then defer to the Asgard APIs to monitor the progress of the deployment and, since Asgard doesn’t have long-term storage, store deployment information so we could track what we’d been up to.
We had originally intended for the service to use Asgard’s functionality to automatically move through the steps of a deployment but found that because we weren’t using Eureka, we needed to be able to get in between those steps and check the health of our services. So the orchestration service was written to operate as a mixture of Asgard actions and custom code which performed ‘in-between’ actions for us.
A deployment consisted of six actions:
create-asg- Use Asgard to create an auto scaling group.wait-for-instance-health- Once the auto scaling group is up and running hit the instances with an HTTP GET and wait for a healthcheck to come back successfully.enable-asg- Use Asgard to enable traffic to the newly-created auto scaling group.wait-for-elb-health- An optional step, wait until the instances from the newly-created auto scaling group are shown as healthy in the load balancer.disable-asg- Use Asgard to disable traffic on the old auto scaling group.delete-asg- Use Asgard to delete the old auto scaling group and terminate its instances.
To us, a deployment is a combination of an AMI and the commit hash from the configuration Git repository for the chosen service and environment. During the creation of the auto scaling group our deployment tooling will create the relevant user-data for the commit hash. If we use the same combination of AMI and commit hash we will get the same code running against the same configuration. This is a vast improvement on our old tooling where we’d have to manually check we’d reset the configuration to the old values.
As we started migrating more services out of the datacenter we found that we wanted more customisation of the deployment process than Asgard provided. We were already running a version of Asgard which had been customised in places and were finding it difficult to keep it up-to-date while maintaining our changes. We made the decision to recreate the deployment process for ourselves and keep Asgard as a very handy window into the state of our AWS accounts.
We stuck to the same naming-conventions as Asgard, which meant that we could still use it to display our information, but recreated the entire deployment process using Clojure. It wasn’t an easy decision to make but it was considered valuable to us to have complete control over our deployment process without pestering the guys at Netflix to merge pull-requests for functionality which was probably useful only to us.
We’re really happy with our Asgard-esque clone. We broke the existing six actions down into smaller pieces and a deployment now runs through over fifty actions for each deployment.
A deployment is still fundamentally the same as before:
- Grab the configuration data for the service and environment we’re deploying it to.
- Generate user-data which will create the necessary environment-specific configuration on the instances.
- Create a launch configuration and auto scaling group.
- Wait for the instances to start.
- Make sure the instances are healthy.
- Start sending traffic to the new instances.
- Once we’re happy with the result the old auto scaling group is deactivated and deleted.
The only difference is that we’re now able to control the ordering of actions at a fine-grained level and quickly introduce new actions when they’re required.
Once a deployment has started the work is all done by the orchestration service as it moves through the actions. A human can only step in to pause a deployment and undo it if there are problems. For a typical deployment a single command will kick off the deployment and the developer can watch the new version being rolled out followed by the old version being cleaned up. Undoing a deployment consists of running the same list of deployment actions, but recreating the old state of the service rather than the new.
Command-line tool
In our whiteboard exercise, people had expressed a preference for CLI-driven deployment tooling which could be used in scripts, chained together etc. so we wanted to prioritise the command-line as the primary method for deploying services, with a web-interface only created for read-only display of information.
We love Hubot and love Hubot in Campfire even more, so we created a command-line application, written in Go, which has become the primary method for developers to carry out a large number of the tasks required when building, deploying and managing our services. We’ve written ourselves a Hubot plugin which allows us to use the command-line application from Campfire, which means that I can kick off that bake I forgot to start before I went to lunch while I’m standing in the queue.
The choice of Go for the tool was an interesting one. We make no secret that we’re big fans of Clojure here at MixRadio but the JVM has a start-up cost which isn’t suitable for a command-line tool that is being used for quick-fire commands. It was a shoot-out between Go, Node.js and Python. In the end Go won because it starts up quickly, can produce a self-contained binary for any platform (so no fiddling with pip or npm) and we wanted to have a go at something new.
Now, the typical workflow for deploying changes to a service looks like this:
# Make awesome changes to a service and commit them
$ klink build search
... Release output tells us we've built version 3.14 ...
# Bake a new image
$ klink bake search 3.14
... Baking output tells us that our AMI is ami-deadbeef ...
# Deploy the new image and configuration to the 'prod' environment
$ klink deploy search prod ami-deadbeef -m "Making everything faster and better"
... Deployment output tells us it was successful ...
# Profit!
Conclusion
Hopefully this overview has given a taste of how we manage deployments here at MixRadio. If there’s anything which unclear then please get in touch with us via the comments below or on Twitter. We value any feedback people are willing to give.
We’re proud of our deployment tooling and are grateful to those who have provided inspiration and the code on which we’ve built.
other posts
- Looking backward (09 Jan 2012)